
by Ilias Diakonikolas (University of Southern California), Santosh Vempala (Georgia Institute of Technology), and David P. Woodruff (Carnegie Mellon University)
Algorithmic High-Dimensional Robust Statistics Fitting a model to a collection of observations is one of the quintessential goals of statistics and machine learning. A major recent advance in theoretical machine learning is the development of efficient learning algorithms for various high-dimensional models, including Gaussian mixture models, independent component analysis, and topic models. The Achilles’ heel of these algorithms is the assumption that data is precisely generated from a model of the given type.
Fitting a model to a collection of observations is one of the quintessential goals of statistics and machine learning. A major recent advance in theoretical machine learning is the development of efficient learning algorithms for various high-dimensional models, including Gaussian mixture models, independent component analysis, and topic models. The Achilles’ heel of these algorithms is the assumption that data is precisely generated from a model of the given type.
This assumption is crucial for the performance of these algorithms: even a very small fraction of outliers can completely compromise the algorithm’s behavior. For example, k adversarially placed points can completely alter the k-dimensional principal component analysis, a commonly used primitive for many algorithms. However, this assumption is only approximately valid, as real data sets are typically exposed to some source of contamination. Moreover, the data corruption is often systematic, and random models do not accurately capture the nature of the corruption. Hence, it is desirable that any estimator that is to be used in practice is stable in the presence of arbitrarily and adversarially corrupted data.
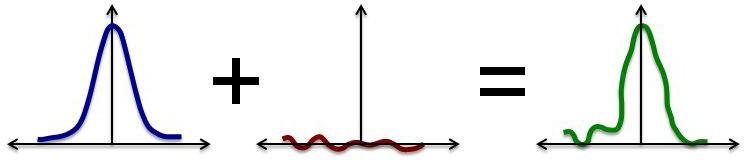
Indeed, the problem of designing outlier-robust estimators is natural enough that it is studied by a classical body of work, namely robust statistics, whose prototypical question is the design of estimators that perform well in the presence of corrupted data. This area of statistics was initiated by the pioneering works of Tukey and Huber in the 1960s and addresses a conceptual gap in Fisher’s theory of exact parametric inference — since parametric models are typically only approximately valid, robust statistics is essential to complete the theory. From a practical perspective, the question of how to make good inferences from data sets in which pieces of information are corrupted has become a pressing challenge. Specifically, the need for robust statistics is motivated by data poisoning attacks, in the context of adversarial machine learning, as well as by automatic outlier removal for high-dimensional data sets from a variety of applications.
Classical work in robust statistics pinned down the fundamental information-theoretic aspects of high-dimensional robust estimation, establishing the existence of computable and information-theoretically optimal robust estimators for fundamental problems. In contrast, until very recently, the computational complexity aspects of robust estimators were poorly understood. In particular, even for the basic problem of robustly estimating the mean of a high-dimensional data set, all known robust estimators were hard to compute (i.e., computationally intractable). In addition, the accuracy of the known efficient heuristics degrades quickly as the dimension increases. This state of affairs prompted the following natural question: can we reconcile robustness and computational efficiency in high-dimensional estimation?
CONTINUE READING Computational complexity theory studies the possibilities and limitations of algorithms. Over the past several decades, we have learned a lot about the possibilities of algorithms. We live today in an algorithmic world, where the ability to reliably and quickly process vast amounts of data is crucial. Along with this social and technological transformation, there have been significant theoretical advances, including the discovery of efficient algorithms for fundamental problems such as linear programming and primality.
Computational complexity theory studies the possibilities and limitations of algorithms. Over the past several decades, we have learned a lot about the possibilities of algorithms. We live today in an algorithmic world, where the ability to reliably and quickly process vast amounts of data is crucial. Along with this social and technological transformation, there have been significant theoretical advances, including the discovery of efficient algorithms for fundamental problems such as linear programming and primality.