1 Introduction
1.1 Lattices and lattice-based cryptography
Lattices are classically-studied geometric objects that in the past few decades have found a multitude of applications in computer science. The most important application area is lattice-based cryptography, the design of cryptosystems whose security is based on the apparent intractability of computational problems on lattices, even for quantum computers. Indeed, lattice-based cryptography has revolutionized the field because of its apparent quantum resistance and its other attractive security, functionality, and efficiency properties.
Intuitively, a lattice is a regular ordering of points in some (typically high-dimensional) space. More precisely, a lattice \( {{\cal{L}}}\) of rank \( {n}\) is the set of all integer linear combinations of some linearly independent vectors \( {\mathbf{b}_1, \ldots, \mathbf{b}_n}\), which are called a basis of \( {{\cal{L}}}\). We will be primarily interested in analyzing the running times of lattice algorithms as functions of the lattice’s rank \( {n}\).
1.2. Computational lattice problems
The two most important computational problems on lattices are the Shortest Vector Problem (SVP) and the Closest Vector Problem (CVP). SVP asks, given a basis of a lattice \( {{\cal{L}}}\) as input, to find a shortest non-zero vector in \( {{\cal{L}}}\). CVP, which can be viewed as an inhomogeneous version of SVP, asks, given a basis of a lattice \( {{\cal{L}}}\) and a target point \( {\mathbf{t}}\) as input, to find a closest vector in \( {{\cal{L}}}\) to \( {\mathbf{t}}\).
Algorithms for solving SVP form the core of the best known attacks on lattice-based cryptography both in theory and in practice. Accordingly, it is critical to understand the precise complexity of SVP as well as possible. The best provably correct algorithms for both SVP and CVP run in \( {2^{n + o(n)}}\)-time [ADRS15, ADS15, AS18a]. The best heuristic algorithms for SVP run in \( {2^{cn + o(n)}}\)-time for \( {c = 0.292}\) classically [BDGL16] and \( {c = 0.265}\) using quantum speedups [Laa15] (see also [KMPR19]), and most real-world lattice-based cryptosystems assume that these algorithms are close to optimal. Indeed, many of these cryptosystems assume what Bos et al. [B+16] call a “paranoid” worst-case estimate of \( {c = 0.2075}\) (based on the kissing number and assuming that sieving algorithms are optimal) as the fastest hypothetical running time for SVP algorithms when choosing parameters. (See also Albrecht et al. [A+18], which surveys the security assumptions made in a wide range of lattice-based cryptosystems.) Accordingly, the difference in being able to solve SVP in \( {2^{0.2075n}}\) versus \( {2^{n/20}}\) versus \( {2^{\sqrt{n}}}\) time may mean the difference between lattice-based cryptosystems being secure, insecure with current parameters, or effectively broken in practice.
There is a rank-preserving reduction from SVP to CVP [GMSS99], so any algorithm for CVP immediately gives an essentially equally fast algorithm for SVP. In other words, CVP is at least as hard as SVP (and probably a bit harder). Indeed, historically, almost all lower bounds for SVP are proven via reduction from CVP (and nearly all algorithmic progress on CVP uses ideas originally developed for SVP).
1.3. Fine-grained hardness
The field of fine-grained complexity works to give strong, quantitative lower bounds on computational problems assuming standard complexity-theoretic assumptions. Proving such a (conditional) lower bound for an \( {{\mathsf{NP}}}\)-hard problem generally works by (1) assuming a stronger hardness assumption than \( {{\mathsf{P}} \neq {\mathsf{NP}}}\) about the complexity of \( {k}\)-SAT (such as ETH or SETH, defined below), and (2) giving a highly efficient reduction from \( {k}\)-SAT to the problem. The most important hardness assumptions for giving lower bounds on \( {{\mathsf{NP}}}\)-hard problems are the Exponential Time Hypothesis (ETH) and the Strong Exponential Time Hypothesis (SETH) of Impagliazzo and Paturi [IP01]. ETH asserts that there is no \( {2^{o(n)}}\)-time algorithm for \( {3}\)-SAT, and SETH asserts that for every \( {\epsilon > 0}\) there exists \( {k \in {\mathbb Z}^+}\) such that there is no \( {2^{(1 – \epsilon)n}}\)-time algorithm for \( {k}\)-SAT, where \( {n}\) denotes the number of variables in the SAT instance.
Here by “highly efficient” reductions we mean linear ones, i.e., reductions that map a \( {3}\)-SAT or \( {k}\)-SAT formula on \( {n}\) variables to an SVP or CVP instance of rank \( {C n + o(n)}\) for some absolute constant \( {C > 0}\). Indeed, by giving a reduction from \( {3}\)-SAT (respectively, \( {k}\)-SAT for any \( {k \in {\mathbb Z}^+}\)) instances on \( {n}\) variables to SVP or CVP instances of rank \( {C n + o(n)}\), we can conclude that there is no \( {2^{o(n)}}\)-time (resp., \( {2^{(1-\epsilon)n/C}}\)-time for any \( {\epsilon > 0}\)) algorithm for the corresponding problem assuming ETH (resp., SETH). Note that the smaller the value of \( {C}\) for which one can show such a reduction, the stronger the conclusion. In particular, a reduction mapping \( {k}\)-SAT instances on \( {n}\) variables to SVP or CVP instances of rank \( {n + o(n)}\) would imply an essentially tight lower bound on the corresponding problem assuming SETH — as mentioned above, the best provably correct algorithms for both SVP and CVP run in time \( {2^{n + o(n)}}\).
1.4. Fine-grained hardness of CVP (and SVP)
It is relatively easy to show that CVP is “ETH-hard,” i.e., to show that a \( {2^{o(n)}}\)-time algorithm for CVP would imply a \( {2^{o(n)}}\)-time algorithm for \( {3}\)-SAT instances with \( {n}\) variables. This would falsify ETH. (It’s a nice exercise to show that the Subset Sum problem on a set of size \( {n}\) reduces to CVP on a lattice of rank \( {n}\), which implies the result.)
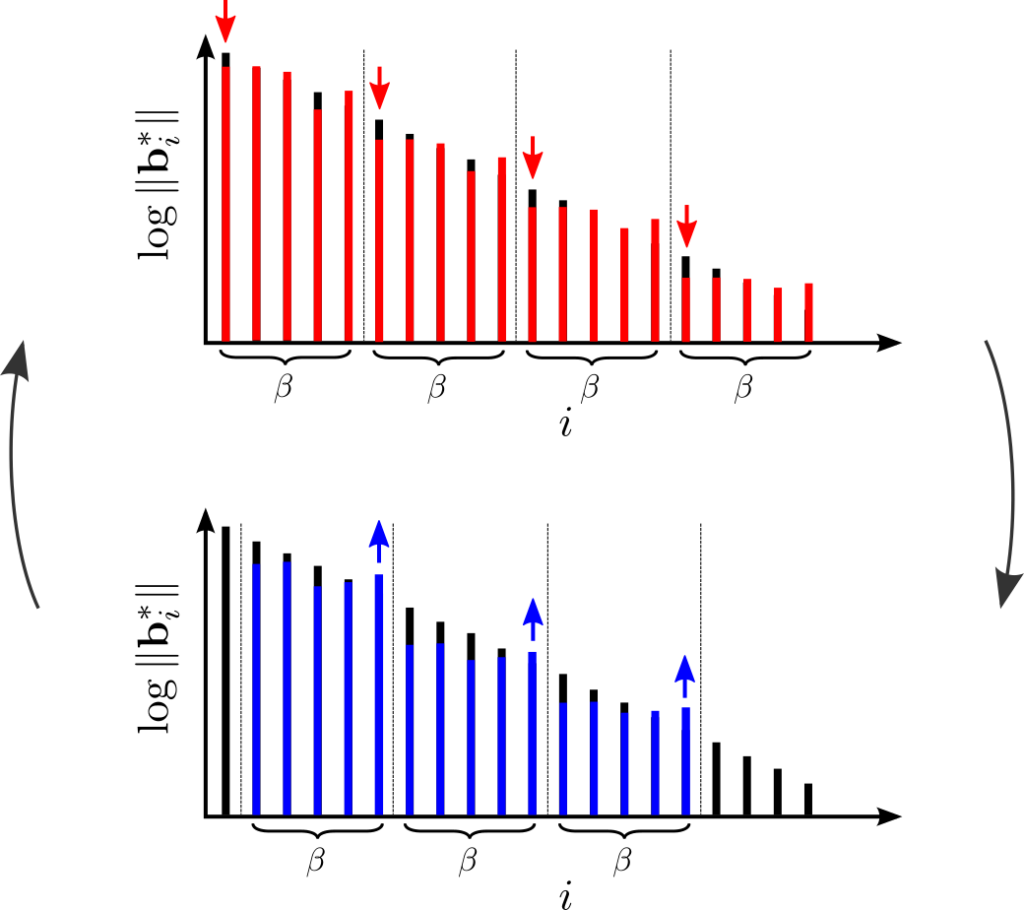
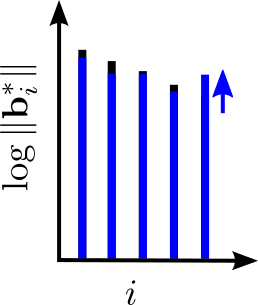
With some work, Divesh Aggarwal and Noah extended this to SVP [AS18b]. In particular, we showed a reduction from CVP to SVP that only increases the rank of the lattice by some constant multiplicative factor. (Formally, the reduction only works with certain minor constraints on the CVP instance. The reduction originally relied on a geometric conjecture, which was open for decades. But, Serge Vlăduţ proved the conjecture [Vlă19] shortly after we published!)
So, unless ETH is false, there is no \( {2^{o(n)}}\)-time algorithm for CVP or SVP. But, for cryptographic applications, even, say, a \( {2^{n/20}}\)-time algorithm would be completely devastating. If such an algorithm were found, cryptographic schemes that we currently think are secure against absurdly powerful attackers straight out of science fiction (say, one with a computer the size of the sun running until the heat death of the universe) would turn out to be easily broken (e.g., in seconds on our laptops).
In [BGS17, ABGS20], we almost showed that CVP is “SETH-hard,” i.e., that a \( {2^{(1-\epsilon)n}}\)-time algorithm for CVP would imply such an algorithm for \( {k}\)-SAT for any constant \( {k}\). This would falsify SETH. So, we almost showed that the [ADS15] algorithm is optimal. The “almost” is because our proof works with \( {\ell_p}\) norms, that is, we show hardness for the version of CVP in which the distance from the target to a lattice vector is defined in terms of the \( {\ell_p}\) norm,
\( \displaystyle \|\mathbf{x}\|_p := (|x_1|^p + \cdots + |x_d|^p)^{1/p} \; . \)
We call the corresponding problem \( {{\mathrm{CVP}}_p}\). In fact, our proof works for all \( {\ell_p}\) norms except when \( {p}\) is an even integer. (To see why this might happen, notice \( {\|\mathbf{x}\|_p^p}\) is a polynomial in the \( {x_i}\) if and only if \( {p}\) is an even integer. In fact, there’s some sense in which “\( {\ell_2}\) is the easiest norm,” because for any \( {p}\), there is a linear map \( {A \in {\mathbb R}^{d \times m}}\) such that \( {m}\) is not too large and \( {\|\mathbf{x}\|_2 \approx \|A \mathbf{x}\|_p}\).) Of course, we are most interested in the case \( {p= 2}\) (the only case for which the [ADS15] algorithm works), which is an even integer! Indeed, for all \( {p \neq 2}\), the fastest known algorithm for CVP is still Ravi Kannan’s \( {n^{O(n)}}\)-time algorithm from 1987 [Kan87]. (For SVP and for constant-factor approximate CVP, \(2^{O(n)}\)-time algorithms are known [DPV11].)
In fact, we showed that for \( {p = 2}\), no “natural” reduction can rule out a \( {2^{3n/4}}\)-time algorithm for CVP under SETH. A “natural” reduction is one with a fixed bijection between witnesses. In particular, any “natural” reduction from \( {3}\)-SAT to CVP must reduce to a lattice with rank at least roughly \( {4n/3}\). So, new ideas will be needed to prove stronger hardness of CVP in the \( {\ell_2}\) norm.
2. Open problems
We now discuss some of the problems that we left open in [BGS17, ABGS20]. For simplicity, we ask for specific results (e.g., “prove that problem \( {A}\) is \( {T}\)-hard under hypothesis \( {B}\)“), but of course any similar results would be very interesting (e.g., “\( {A}\) is \( {T’}\)-hard under hypothesis \( {B’}\)“).
2.1. Hardness in the \(\ell_2\) norm
The most obvious question that we left open is, of course, to prove similar \( {2^n}\)-time hardness results for \( {{\mathrm{CVP}}_2}\) (and more generally for \( {{\mathrm{CVP}}_p}\) for even integers \( {p}\)).
Open problem 1. Show that there is no \( {2^{0.99 n}}\)-time algorithm for \( {{\mathrm{CVP}}_2}\) assuming SETH.
Remember that we showed that any proof of such a strong result would have to use an “unnatural” reduction. So, a fundamentally different approach is needed. One potentially promising direction would be to find a Cook reduction, as our limitations only apply to Karp reductions.
Alternatively, one might try for a different result that gets around this “natural” reduction limitations. E.g., even the following much weaker result would be very interesting.
Open problem 2. Show an efficient reduction from \( {3}\)-SAT on \( {n}\) variables to \( {{\mathrm{CVP}}_2}\) on a lattice of rank \( {\approx 10n}\).
Such a reduction to \( {{\mathrm{CVP}}_2}\) on a lattice of rank \( {Cn}\) for some large constant \( {C}\) is known by applying the Sparsification Lemma [IPZ01] to \( {3}\)-SAT, but showing such a reduction for any reasonably small \( {C}\) or even any explicit \( {C}\) using a different proof technique would be interesting.
Also, our limitations only apply to reductions that map satisfying assignments to exact closest vectors. So, one might try to get around our limitation by working directly with approximate versions of \( {3}\)-SAT and \( {{\mathrm{CVP}}_2}\). (In [ABGS20], we show such reductions from Gap-\( {k}\)-SAT to constant-factor approximate \( {{\mathrm{CVP}}_p}\) for all \( {p \notin 2{\mathbb Z}}\) as well as all \( {k \leq p}\). We also show reductions from Gap-\( {k}\)-Parity that achieve relatively large approximation factors.)
Open problem 3. Show an efficient reduction from Gap-\( {3}\)-SAT on \( {n}\) variables to approximate \( {{\mathrm{CVP}}_2}\) on a lattice of rank \( {n}\).
2.2. Hardness in \(\ell_p\) norms
Intuitively, one reason that we are able to prove such strong results for \( {\ell_p}\) norms for \( {p \neq 2}\) is because we can use lattices with large ambient dimension \( {d}\) but low rank \( {n}\). In other words, while our reductions produce lattices \( {{\cal{L}}}\) that live in some \( {n}\)-dimensional subspace of \( {\ell_p}\)-space, the ambient space itself has large dimension \( {d}\) relative to \( {n}\). Of course, any subspace of the \( {\ell_2}\) norm is an \( {\ell_2}\) subspace (i.e., every slice of a ball is a lower-dimensional ball), so in the \( {\ell_2}\) norm, one can assume without loss of generality that \( {d = n}\). In particular, if we were able to prove \( {2^n}\)-hardness for the \( {\ell_2}\) norm, then we would actually prove \( {2^d}\)-hardness for free. However, a potentially easier problem would be to improve the \( {2^n}\)-hardness of \( {{\mathrm{CVP}}_p}\) shown in [BGS17, ABGS20] to \( {2^d}\)-hardness for some \( p \neq 2 \).
Open problem 4. Show that there is no \( {2^{0.99 d}}\)-time algorithm for \( {{\mathrm{CVP}}_p}\) (for some \( {p}\)) assuming SETH.
More generally, it would be very interesting to settle the fine-grained complexity of \( {{\mathrm{CVP}}_p}\) for some \( {p \neq 2}\) (either in terms of rank \( {n} \) or dimension \( {d} \)). This could take the form either of showing improved algorithms (currently the fastest algorithms for \( {{\mathrm{CVP}}_p}\) for general \( {p}\) run in \( {n^{O(n)}}\)-time [Kan87], and \( {2^{O(n)}}\)-time for a constant approximation factor [DPV11]), or showing super-\( {2^n}\) hardness, or both.
Open problem 5. Show matching upper bounds and lower bounds (under SETH) for \( {{\mathrm{CVP}}_p}\) for some \( {p}\) (possibly with a constant approximation factor).
The case where \( {p = \infty}\) is especially interesting. Indeed, because the kissing number in the \( {\ell_\infty}\) norm is \( {3^n-1}\), one might guess that the fastest algorithms for \( {{\mathrm{CVP}}_\infty}\) and \( {{\mathrm{SVP}}_\infty}\) actually run in time \( {3^{n + o(n)}}\) or perhaps \( {3^{d + o(d)}}\). (See [AM18], which essentially achieves this.) We therefore ask whether stronger lower bounds can be proven in this special case.
Open problem 6. Show that \( {{\mathrm{CVP}}_\infty}\) cannot be solved in time \( {3^{0.99n}}\) (under SETH).
2.3. Hardness closer to crypto
The most relevant problem to cryptography is approximate \( {{\mathrm{SVP}}_2}\) with an approximation factor that is polynomial in the rank \( {n}\). Our fastest algorithms to solve this problem work via a reduction to exact (or near exact) \( {{\mathrm{SVP}}_2}\) with some lower rank \( {n’ = \Theta(n)}\), so that even for these polynomial approximation factors, our fastest algorithms run in time \( {2^{\Omega(n)}}\) (where the hidden constant depends on the polynomial; see Michael’s post for more on this topic). And, hardness results for exact SVP rule out attacks on cryptography that use such reductions. We currently only know how to rule out \( {2^{o(n)}}\)-time algorithms for \( {{\mathrm{SVP}}_2}\) (under the Gap-ETH assumption). We ask whether we can do better. (In [AS18b], we proved the stronger result below for \( {\ell_p}\) norms for large enough \( {p \notin 2{\mathbb Z}}\).)
Open problem 7. Prove that there is no \( {2^{n/10}}\)-time algorithm for \( {{\mathrm{SVP}}_2}\) (under SETH).
Of course, we would ideally like to directly rule out faster algorithms for approximate \( {{\mathrm{SVP}}_2}\) with the approximation factors that are most directly relevant to cryptography. There are serious complexity-theoretic barriers to overcome to get all the way there (e.g., \( {{\mathrm{CVP}}_p}\) and \( {{\mathrm{SVP}}_p}\) are known to be in \( {{\mathsf{NP}}} \cap {{\mathsf{coNP}}}\) for large enough polynomial approximation factors. But, we can still hope to get as close as possible, by proving stronger hardness results for approximate \( {{\mathrm{CVP}}_p}\) and approximate \( {{\mathrm{SVP}}_p}\). Indeed, a beautiful sequence of works showed hardness for approximation factors up to \( {n^{c/\log \log n}}\) (so “nearly polynomial) [DKRS03, HR12], but these results are not fine grained.
The best fine-grained hardness of approximation results known rule out algorithms for small constant-factor approximations for \( {{\mathrm{CVP}}_p}\) with \( {p \notin 2{\mathbb Z}}\) in time \( {2^{0.99n}}\) for \( {{\mathrm{CVP}}_p}\) and \( {{\mathrm{SVP}}_p}\) for any \( {p}\) in time \( {2^{o(n)}}\). We ask whether we can do better.
Open problem 8. Prove that there is no \( {2^{0.99 n}}\)-time algorithm for \( {2}\)-approximate \( {{\mathrm{CVP}}_p}\) (under some form of Gap-SETH, see below).
Open problem 9. Prove that there is no \( {2^{o(n)}}\)-time algorithm for \( {\gamma}\)-approximate \( {{\mathrm{CVP}}_p}\) for superconstant \( {\gamma = \omega(1)}\) (under Gap-ETH).
2.4. Gap-SETH?
One issue that arose in our attempts to prove fine-grained hardness of approximation results is that we don’t even know the “right” complexity-theoretic assumption about approximate CSPs to use as a starting point. For fine-grained hardness of exact problems, ETH and SETH are very well established hypotheses, and they are in some sense “the weakest possible” assumptions of their form. E.g., it is easy to see that \( {k}\)-SAT is \( {2^{Cn}}\) hard if any \( {k}\)-CSP is. But, for hardness of approximation, the situation is less clear.
The analogue of ETH in the regime of hardness of approximation is the beautiful Gap-ETH assumption, which was defined independently by Irit Dinur [Din16] and Pasin Manurangsi and Prasad Raghavendra [MR17]. This assumption says that there exists some constant approximation factor \( {\delta \neq 1}\) such that \( {\delta}\)-Gap-\( {3}\)-SAT cannot be solved in time \( {2^{o(n)}}\). (Formally, both Dinur and Manurangsi and Raghavendra say that there is no \( {2^{o(n)}}\)-time algorithm that distinguishes a satisfiable formula from a formula for which no assignment satisfies more than a \( {(1-\epsilon)}\) fraction of the clauses, but we ignore this requirement of perfect completeness here.) It is easy to see that this hypothesis is equivalent to a similar hypothesis about any \( {3}\)-CSP (or, indeed, any \( {k}\)-CSP for any constant\( {k}\)).
However, to prove hardness of approximation with the finest of grains, we need some “gap” analogue of SETH, i.e., we would like to assume that for large enough \( {k}\), some Gap-\( {k}\)-CSP is hard to approximate up to some constant factor \( {\delta \neq 1}\) in better than \( {2^{0.99n}}\)-time. (Formally, we should add an additional variable \( {\epsilon > 0}\) and have such a hypothesis for every running time \( {2^{(1-\epsilon)n}}\), but we set \( {\epsilon = 0.01}\) here to keep things relatively simple.)
An issue arises here concerning the dependence of the approximation factor \( {\delta}\) on the arity \( {k}\). In particular, recall that \( {k}\)-SAT can be trivially approximated up to a factor of \( {1-2^{-k}}\) (since a random assignment satisfies a \( {1-2^{-k}}\) fraction of the clauses in expectation). So, if we define Gap-SETH in terms of Gap-\( {k}\)-SAT, then we must choose \( {\delta = \delta(k) \geq 1-2^{-k}}\) that converges to one as \(k\) increases. Manurangsi proposed such a version of Gap-SETH in his thesis [Man19, Conjecture 12.1], specifically that for every large enough constant \( {k}\) there exists a constant \( {\delta = \delta(k) \neq 1}\) such that Gap-\( {k}\)-SAT cannot be approximated up to a factor of \( {\delta}\) in time \( {2^{0.99n}}\). (Again, we are leaving out an additional variable, \( {\epsilon}\).)
If we rely on this version of Gap-SETH, then our current techniques seem to get stuck at proving hardness of approximation for, say, \( {\gamma}\)-approximate \( {{\mathrm{CVP}}_p}\) for some non-explicit constant \( {\gamma_p > 1}\) (and, if one works out the numbers, one can see immediately that \( {\gamma_p}\) must be really quite close to one). However, other Gap-\(k\)-CSPs are known to be (\(\mathsf{NP}\)-)hard to approximate up to much better approximation factors. E.g., for any \( {k}\), Gap-\(k\)-Parity is \( {{\mathsf{NP}}}\)-hard to approximate up to any constant approximation factor \( {1/2 < \delta \leq 1}\) [Hås01], and Gap-\( {k}\)-AND is \( {{\mathsf{NP}}}\)-hard to approximate for any constant approximation factor \( {\Omega(k/2^k) \leq \delta \leq 1}\) [Cha16]. Indeed, Gap-\( {k}\)-AND is a quite natural problem to consider in this context since there is a fine-grained, approximation-factor preserving reduction from any Gap-\( {k}\)-CSP to Gap-\( {k}\)-AND. This generality motivates understanding the precise complexity of Gap-\( {k}\)-AND.
Open problem 10. What is the fine-grained complexity of the \( {\delta}\)-Gap-\( {k}\)-AND problem in terms of \( {n}\), \( {k}\), and \( {\delta}\)? In particular, if
\( \displaystyle C_{k,\delta} := \inf \{ C > 0 \ : \ \text{there is a $2^{C_{k,\delta}}$-time algorithm for algorithm for $\delta$-Gap-$k$-AND}\}\)
then what is the behavior of \( {C_{k,\delta}}\) as \( {k \rightarrow \infty}\) (for various functions \( {\delta = \delta(k)}\) of \( {k}\))?
In particular, if one were to hypothesize sufficiently strong hardness of \( {\delta}\)-Gap-\( {k}\)-AND — i.e., to define an appropriate variant of Gap-SETH based on Gap-\( {k}\)-AND — then one might be able to use this hypothesis to prove very strong fine-grained hardness of approximation results. There is a fine-grained (but non-approximation preserving) reduction from Gap-\( {k}\)-AND to Gap-\( {k}\)-SAT, and so Manurangsi’s Gap-SETH is equivalent to the conjecture that there exists some non-explicit \( {\delta(k)}\) such that \( {\lim_{k \rightarrow \infty} C_{k,\delta} = 1}\).
- [ABGS20] Aggarwal, Bennett, Golovnev, Stephens-Davidowitz. Fine-grained hardness of CVP(P)— Everything that we can prove (and nothing else)
- [A+18] Albrecht, Curtis, Deo, Davidson, Player, Postlethwaite, Virdia, Wunderer. Estimate all the {LWE, NTRU} schemes! SCN, 2019.
- [ADRS15] Aggarwal, Dadush, Regev, Stephens-Davidowitz. Solving the Shortest Vector Problem in \(2^n\) time via discrete Gaussian sampling. STOC, 2015.
- [ADS15] Aggarwal, Dadush, Stephens-Davidowitz. Solving the Closest Vector Problem in \(2^n\) time–The discrete Gaussian strikes again! FOCS, 2015.
- [AM18] Aggarwal, Mukhopadhyay. Faster algorithms for SVP and CVP in the \(\ell_\infty\) norm. ISAAC, 2018.
- [AS18a] Aggarwal, Stephens-Davidowitz. Just take the average! An embarrassingly simple \(2^n\)-time algorithm for SVP (and CVP). SOSA, 2018.
- [AS18b] Aggarwal, Stephens-Davidowitz. (Gap/S)ETH hardness of SVP. STOC, 2018.
- [B+16] Bos, Costello, Ducas, Mironov, Naehrig, Nikolaenko, Raghunathan, Stebila. Frodo: Take off the ring! Practical, Quantum-Secure Key Exchange from LWE. CCS, 2016.
- [BDGL16] Becker, Ducas, Gama, Laarhoven. New directions in nearest neighbor searching with applications to lattice sieving. SODA, 2016.
- [BGS17] Bennett, Golovnev, Stephens-Davidowitz. On the quantitative hardness of CVP. FOCS, 2017.
- [Cha16] Chan. Approximation resistance from pairwise-independent subgroups. J. ACM, 2016.
- [Din16] Dinur. Mildly exponential reduction from gap 3SAT to polynomial-gap label-cover.
- [DKRS03] Dinur, Kindler, Raz, Safra. Approximating CVP to within almost-polynomial factors is NP-hard. Combinatorica, 2003.
- [DPV11] Dadush, Peikert, Vempala. Enumerative lattice algorithms in any norm via \(M\)-ellipsoid coverings. FOCS, 2011.
- [GMSS99] Goldreich, Micciancio, Safra, Seifert. Approximating shortest lattice vectors is not harder than approximating closest lattice vectors. IPL, 1999.
- [Hås01] Håstad. Some optimal inapproximability results. J. ACM, 2001.
- [HR12] Haviv, Regev. Tensor-based hardness of the Shortest Vector Problem to within almost polynomial factors. TOC, 2012.
- [IP01] Impagliazzo, Paturi. On the complexity of \(k\)-SAT. JCSS, 2001.
- [IPZ01] Impagliazzo, Paturi, Zane. Which problems have strongly exponential complexity? JCSS, 2001.
- [Laa15] Laarhoven. Search problems in cryptography. Ph.D thesis, 2015.
- [Kan87] Kannan. Minkowski’s convex body theorem and Integer Programming. MOR, 1987.
- [KMPR19] Kirshanova, Mårtensson, Postlethwaite, Roy Moulik. Quantum algorithms for the approximate \(k\)-list problem and their application to lattice sieving. Asiacrypt, 2019.
- [Man19] Manurangsi. Approximation and Hardness: Beyond P and NP.
- [MR17] Manurangsi, Raghavendra. A Birthday Repetition Theorem and Complexity of Approximating Dense CSPs. ICALP, 17.
- [Vlă19] Vlăduţ. Lattices with exponentially large kissing numbers. Moscow J. of Combinatorics and Number Theory, 2019.

 In the Simons Institute program on Proofs, Consensus, and Decentralizing Society, systems like Stellar reminded us of the anomaly that results from introducing cryptography into distributed computing.
In the Simons Institute program on Proofs, Consensus, and Decentralizing Society, systems like Stellar reminded us of the anomaly that results from introducing cryptography into distributed computing.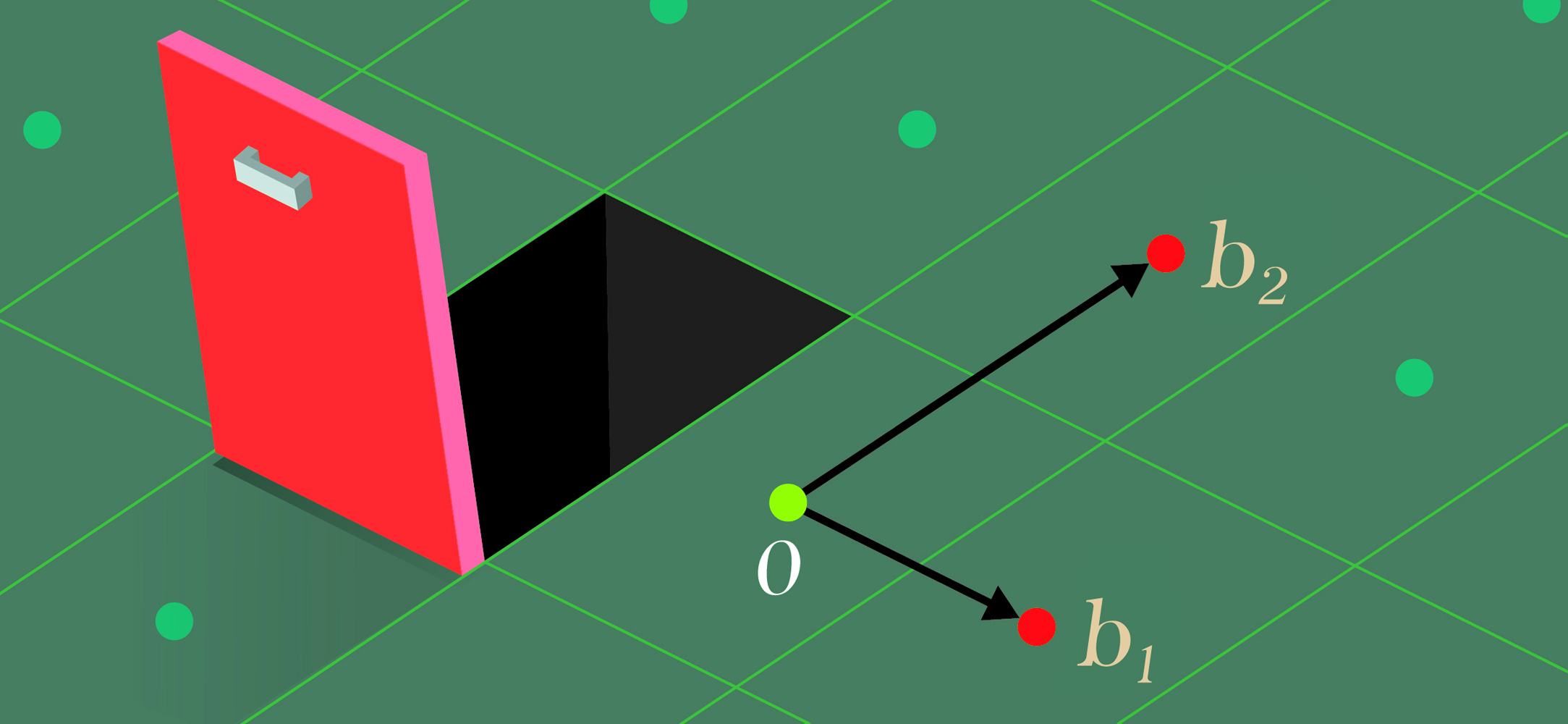 One of the most fascinating things about cryptography is its deeply paradoxical nature: among its early successes is the ability for two strangers to meet, generate a shared secret key, and thereon communicate privately — all of these
One of the most fascinating things about cryptography is its deeply paradoxical nature: among its early successes is the ability for two strangers to meet, generate a shared secret key, and thereon communicate privately — all of these 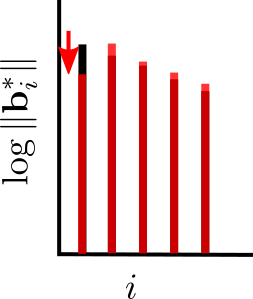
 In January 2014, during an open problems session in the auditorium at the Simons Institute, the computer scientist Thomas Vidick posed a question that he expected would go nowhere.
In January 2014, during an open problems session in the auditorium at the Simons Institute, the computer scientist Thomas Vidick posed a question that he expected would go nowhere. Amid the biggest pandemic in a century, one that has disrupted lives and livelihoods the world over, it is gratifying to see how people in different walks of life have found ways to cope and carry on. Within the realm of theory research, the pursuit to better understand the foundations of computation and their implications doesn’t seem to have slowed down even a bit.
Amid the biggest pandemic in a century, one that has disrupted lives and livelihoods the world over, it is gratifying to see how people in different walks of life have found ways to cope and carry on. Within the realm of theory research, the pursuit to better understand the foundations of computation and their implications doesn’t seem to have slowed down even a bit.
 An emerging theme in several disciplines of science over the last few decades is the study of local-to-global phenomena. Let me elucidate with a few examples. In biology, one tries to understand the global properties of an organism by studying local interactions at a cellular level. The Internet graph is impossible to predict or control at a global level; what one can at best do is understand its behavior by making changes at a very local level. Moving to examples closer to theoretical computer science, the pioneering works in computation theory due to Turing and others define the computation of any global function as one that can be broken down into a sequence of local computations. The seminal work on NP-completeness due to Cook, Levin, and Karp demonstrates that any verification task can be in fact reduced to a conjunction of verifying very local objects.
An emerging theme in several disciplines of science over the last few decades is the study of local-to-global phenomena. Let me elucidate with a few examples. In biology, one tries to understand the global properties of an organism by studying local interactions at a cellular level. The Internet graph is impossible to predict or control at a global level; what one can at best do is understand its behavior by making changes at a very local level. Moving to examples closer to theoretical computer science, the pioneering works in computation theory due to Turing and others define the computation of any global function as one that can be broken down into a sequence of local computations. The seminal work on NP-completeness due to Cook, Levin, and Karp demonstrates that any verification task can be in fact reduced to a conjunction of verifying very local objects.